|
|
| �Ĥ@�������r�Ƿ|�dzN�Q�|�E�Ѭz 1996�~8��25-30�� �q�l�j�y�����ʦr���D |
| Page 3 of 8 |
| �L�B��r���Ѧb�q�������F
�p�e�z�A�ѨM�ʦr���D������b��p����r���Ѧ��t�Φa���F�b�q�����C�b�H�U�Ĥ@�`���N���ԭz�@�Ǭ������I���A�M����i���t�ι��r���Ѫ��F�����k�C
�@�B�I�� �b���`�����Q�פG�h���t�ΩҤޥΥH�e����s�A�ù�ثe�q���������p�@�@�����C(�@)�B����q���Φr 1970�~�e���A�x�W�a�϶}�l�����Q�ιq���B�z�~�r����D�C�M���A���ɤ�r�έp��ƨä������A�]�S���@�ӾA�����~�r�r���i�ѹq���ĥΡC1971�~�b���w���q�٧U�U�A��q�j�ǭp��P����t�e���L�����ͱq�ơu����q���Φr�v����s�C �Ӭ�s�q1971�~10���i�}�A�H�G�d�h�H�u�@���A���g�b�~�A��1972�~3�멳���X��B���i�C�{�N�Ӭ�s���@�ǯS��έ��n��h���C�G
���r�����i�Ȭ�9.60�A�e500�r�ϥβ��W�Ԧp�e���T�f�C�ѩ�b�x�W�èS����n����r�έp��ƥX�{�A�ҥH���t�Τ��H���r���@�ť��C ���@�m����q���Φr���n�����Q�@�ئr�J ���G�m����q���Φr���n����r����z��h ���G���ϡ������ܡu���n�W�V�v�A�p��50%���ܫe141�r���ֿn�ϥ��W�v���W�L50%�C (�G)�B��j�r�ڨt�� �b�x�W�A�̦����R�~�r�r�ڪ��O��q�j���A�o�M�r�ڴN�R�W���m��j�r�ڶ��n�C1972�~�A�ٯ��b�Ӥh�פ�m�����r�����c�Ҧ��Ψ���R�n���A���դF�Q�X�ر`�Ϊ��c�r�覡�A�òέp��ϥΤ��W���A�o�{�u�ξ�V�s���B���V�s���M�]�t�o�T�زզX�覡�A�N�i�H�j�T��²�~�r�����c�A�l�̬Ƥ֥Υi���Ӥ��p�C�ڦ��A�~�r���c���r�ڨ���F��k�T�w�F�U���A�p�e���|�f�ҥܡC���| �~�r�r�ε��c������F�]�HBakcus Normal Form���ܡ^
|
�e���|�f�����c�r�t�άO�HBNF�]Bakcus Normal Form�^����y�k�]formal
grammar�^���F���C���O�@�شF�ͨt�Ρ]production
system�^�A��Y�G�i�ѳ̩��U������Ÿ��A�p�q�r�ڡr�B�q�w��Ÿ��r�o�DzŸ����X(set)���������A�̪��������l�F�ͬ��s���Ÿ��A�p�~�r�γ���C�@��ӻ��A�o�شF�ͨt�ίಣ�ͪ��A�`�h���ΤW�һݭn���A�ҥH�����[�@�Ǩϥα��ҡ]�y�N�^�������A�Ӱt�X�{�ꪺ���ҡCĴ�p�G���t�β��ͪ����A�s���O����H�O�r�H�Ϊ̤����O�A�O�ϥΪ̥i�H�P�_��ܪ��C�]���]�p���A�ᤩ�F���t�Τ������K�����I���ӳy�s�r���u�ʡC�b���t�Τ��A�q�r�ڡr�O�q����r���l���X(subset)�A�N���̰B���i�A���Ѫ��@�s����C�r�ڲզ������A����զ��~�r�C�~�r�B����B�r�ڳ��i�ΨӲզX���c�Χ�������~�r�C�ѩ�q�~�r�r�B�q����r�B�q�r�ڡr�o�T�Ӷ��X�������|���B�A�b�ϥΤW�A�q����r�`�Ψӫ����ݩ�~�r�]���ݩ�r�ڪ����@�s�����C�p�e�Ϥ@�f�����Ҥl�A�W�M�s�O�~�r�A���ݩ��A�}�B���B�t�O�~�r�]�O�r���A���O�r�ڡC�Ϥ��r�ڻP�������������Y�e�ỡ���C
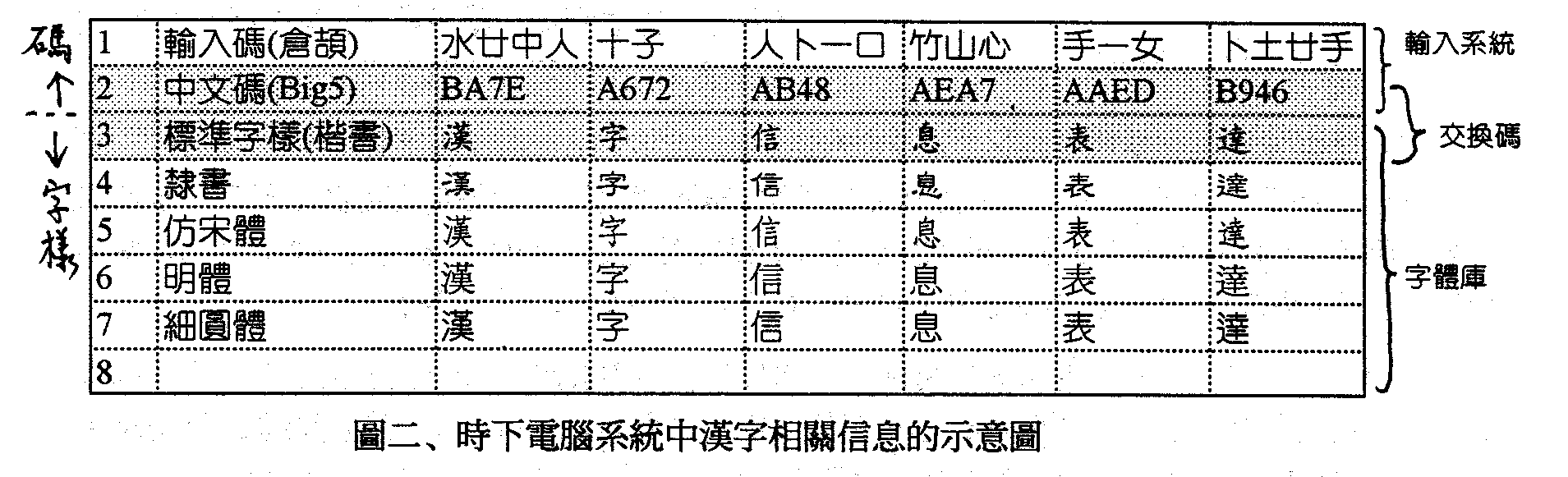
 �Ϥ@�G�W�r���c�� �ٯժ��u�@�O�M�L���z�m����q���Φr���n�P�ɰ����A�r�ڪ��T�w�O����@�P�V�O�����G�C�o�M�r�ڦ��@�S���A���O�g�L���ФT���u�̨Τơv�ӱo�쪺�C�ҿ׳̨Τ��A�O���b�r���`�ƩM�����C�Ӧr���Ѫ��r�ڼƥء]�g�ϥ��W�v�[�v�p��^��̤����A�D�@����̨Ϊ����G�C�q�`�A�r�ڶV�h�A�C�Ӧr���ѫ᪺�r�ڼƴN�V�֡F�r�ڶV���A�h�C�Ӧr���r�ڴN�V�h�C�b�ϥΤ譱�A�ڭ̬O�J�Ʊ�r�ڤ��A�]�Ʊ�C�Ӧr���r�ڤ��A�ҥH�b�����i�ݱo�����ΤU�A�u���D��̨Τ��զX�C���̨ΤƬO�g�L�@�Ǽƾǭp��]�٬���ڮĥέ�h�^�ӨM�w���C�䵲�ײ��p�G�Z�@�Ӧr��ϥ��W�v�b�U����37.58�H�W���A���������A�b�U����18.79��37.58�����̤��i���Ѭ���ӥH�W���r���A�b12.36��18.79�����̤��i���Ѭ��T�ӥH�W�r���A�b9.39��12.36�����̤������Ѭ��|�ӥH�W���r���A�l�̵L�������A�S���jê�C�i���T�j �o�ӵ����A�]�M�w�F���Ѻ~�r�����u�C �̾ڡm����q���Φr���n����9129�Ӧr���A�v�r���Ѧӱo496�r���A�Ш��e�����f�A�䤤�t���`�μ��r305�ӡ]�䤤39�ӬO�X�i���ѱ���̡^�A���`�p�ϥ��W�v�w�W�L������50%�C�Y�̦r�ڪ��ϥ��W�v�έp�A�̱`�Ϊ��e25�Ӧr�ڤw�������ϥ��W�ת�30%�A�e50�Ӭ�49%�A�e100�Ӭ�66.7%�A�e200�Ӭ�84.9�H�A�e300�Ӭ�95%�C�i���|�j �̨Τƪ����G�O�A�̨ϥ��W�v�[�v�᪺�����C�Ӧr���r�ڼƶ�1.9�C�ܩ�o�M�r�ںc�r���Ҧ��i�H�A�Ψ줰��{�שO�H�N�i������sġ���m����j���n��49905�r�v�r�ָ��A�p�i�զX48713�r�A��1129�r���H�զX�A�o�Ǧr�h��ó���A�f�r�A�Τ@�ǥj��B�Ϥ�B���ˤ����̡C���h�����N�A�Φ��w�o�ΡC�g�Ҽ{���A�å��N���ǤJ��j�r�ڨt�Τ��C�p��ᦳ���ݭn�A�A�N��1129�r�A�ǤJ����C���c�r���ʽ西�O���t�ΩҧƱ檺�A�ҥH���t�Υ�H������¦�å[�H�X�R�C �r�ڨt�άO�~�r�r�ε��c�����@�Ӱ����A���O�̷��ѵo�i�X�Ӫ��A�èS���Ҽ{��f�B���B��B�r���A�]�S���U�ήѪk�ΦU�ئL��r�����ܤơC����x�����A�u�O�q���ѥ~�[�W�Ӵy�z�~�r���c���A�Y�Ϧp���A�o�c�����H���٬O�W�z�U�r��B�r�����@�P�����A�O�i�ѦU��ѦҧQ�Ϊ��C�ܩ�U�骺�r���ܤƴy�z�A�Ԧp���C ���� ��j����r�ڪ� 
�@ (�T)�B�ثe�q������r���� �ɤU�q���t�Τ��w�s�J���~�r�H�����G�洫�X�����r�ˡB�r�X�M�r�ǡF�r���w�����U��r���A�H�Υ��̩M�洫�X����M�F��J�t�Τ�����J�X�Τ@�Ǻ~�r�ݩʡA�H�Υ��̩M�洫�X����M�C�o�ǫH���Ω��������p���p�e�ϤG�f�C
|
| �洫�X�������r�Ǫ��H���A���`�`�ä�����A�p�e�z���y�r���N�ε��F�즳���r�ǡC���~�A���ǽX�õL�@�P���r�ǡA�pJIS���e�b�Ӫ`���ƧǡA��b�o�ӳ��������ơA�o�ä����ܦr�Ǫ��H���״I�A�ϦӬO�U�ӱƧǪ��H�����u���@�b�A�Өϱo�q���L�k�̬Y�سW�h��Ҧ���r�ƧǡC�o�ئr�Ǫ���λ��ȬO�ܤ֪��A�X�G������L�C�A���A�X�G�Ҧ����t�γ��S����r�Ǫ��@�ǭ��n���Ъ��H����z�X�ӡCĴ�p�G�ĤQ�����r�O�q����X�ƨ줰��X�A�Y�������r�O�q���쨺��C�S���o�ǫ��СA�ϥΪ̫��Φr�ǫH���O�H
���ǿ�J�t�Φs���@�Ǻ~�r���ݩ��A�p�`����J�k���N���C�Ӧr�����СC�i�O�A�o�ǭ��Цh�b�S���������Ҧ����}���A�]�S���B�z�}������k�C�аݭn��J�u���v�r���A�Ӧp��`���H�]���A�o�����H���u�O�j�j�����I�~�r��J���A�èS�����U�����γ]�Q�C�ƪ��A���Ǩt�ήڥ������ϥΪ̨��γo�����H���C
�ѥH�W�����άݨ��A�q�������~�r�H�����Ȥֱo�i���A��O���ѥ��աC�o�N�Ǥ��o�����ή�ê��ê�}�F�C�o��b�O����q�����ΤW�����ư����̸}�ۡC
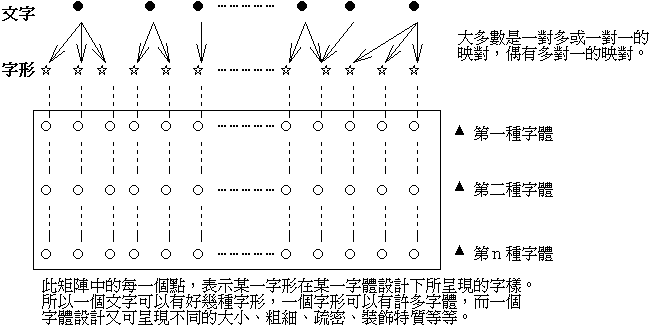
�G�B��r����w�q�P���F �r�B�r�ΡB�r��o�ǦW���b�ڭ̻y�Τ��`�`�N���ۤ��ɬۦP���N���A�����H�����A�ڭ̨ä�ı�o�����q����ê�C�i�O�A�q�����S���H�F���A�]�S���ҥi�ѷ��A�ҥH���ݹ�o�ǦW���@����ɩw�A�q���~��ڥH���Q�a�B�z��r�H���C���`�N�����@��������b���t�Τ����u�@�w�q�C �r(character)�O���F�@�ةΤ@�s�������W�ۡC���O��H���A�H�y�N�ϧO�C�Ҧp�A�������c��M²��O�P�@�Ӧr�C�b�q�����A�r�Τ@���ѧO�X(identifier)�����A���ѧO�X�i�H�O�洫�X�A�]�i�H�O�����B�z��K�ϥΪ��u���X�v�A�άO��J�ɪ��u��J�X�v�C����K�p�A�H�U���Q�ק��H�洫�X�ӥN���r�C�ثe�A�r�ҩӸ����y�N�٨S����F�b�t�Τ��A�ҥH�q���èS����k�i�H�����B�z�y�N�H���C �p�e�ҭz�A�@�Ӧr�i��\�h�r��(glyph)�C�r�Τ]��H���A�ϧO�r�Ϊ�����b���զ����c�A��Y�c�r�A�p�e���A�c��M²���ݩP���r�ΡC�����A�]���Ǧr�|�ΦP�@�r�Ϊ��C�ҥH�A�H�ƾ����Y�ӻ��A�r����r�Τj�h�ƬO�@��@�Τ@��h�����Y�A�����ҥ~�C �r�Υu�ɩw�c�r�A�ä����߸Ӧr�n���n�ݡC�̦P�@�W�d�s�@���@�s�r�ݩ�P�@�ئr��(font)�C�r��]�O��H���A�ϧO������b���]�p�W�d�C���M�r�馳�]�p�W�d�H���{�乺�@���S���A���������N�Ч@���Ŷ��A���\�]�p�̪��{�ۤv������C�ҥH�A�P�@�r��U�U�t�ӳ]�p���u�r���]style�^�v�|�{�X���P�������B�����C�@�ئr���]�p�A�q�`���ǰѼƨӨM�w���e�{���j�p�B�ʲӡB��ʲӤ�C�B���K�H�Τ@�ǯS���˹����䨤�����C�ݳo�ǰѼƿ�w�F�A�~��ɴC���e�{�X�o�Ӧr�������A���٬��r��(typeface)�C�ߦ��r�ˤ~�O����i�����C�Ӳz���A�o�Ǧr��M�r���b�]�p�W���ͪ��Ϊ��ܤơ]�H�U²�٬��r���ܤơ^�O�����ӹH�Ϻc�r�W�ߡ]�Y�r�Ϊ��w�q�^���A�M�Ӧb��ȤW�èS���o���Y���A�]�y���F�Ǧr�ΤW���t���A�ԲӪ����R�p���C �W�z�����Y�i�Ѩ��e�ϤT�f�C�ҿפ�r������F�A�Y�N�e�ϤT�f�������Y�ιq����F�Ѫ��覡�A���F�b�q�����C�r�����F�w�p�e�z�C�r�骺�H���s�b�r��w(font library)���A�o�O�j�a���ߪ��A��e�h���A�Ѩ��e�ϤG�f�C�ثe�q�����L�r�ΫH���A�Ϊ̻��O�r�P�r�Τ����A�V�c�ۥ��A�ҥH�L�k���O�γB�z����r�C�r�θ�Ʈw�N�O�n��ɳo�Ӫů��A���֦��r�P�r�ζ����Y����M�A�H�Φr�Ϊ����c�Ҧ��A�p�U��C
|
| Page 3 of 8 |
|
�@