|
|
| ș~ŠrŠrœX»PžêźÆźw°ê»ÚŹă°Q·|ĄAšÊłŁĄEȘFšÊ 1996Š~10€ë4€é ±qŻÊŠr°ĘĂDĄAœÍș~Šr„掫œXȘș«·sł]pąwąwČÄ€GłĄ€À A Descriptive Method for Re-engineering Hanzi |
| Page 4 of 9 |
| 2. The Representation of Hanzi
Knowledge
(3)A Glyph Model
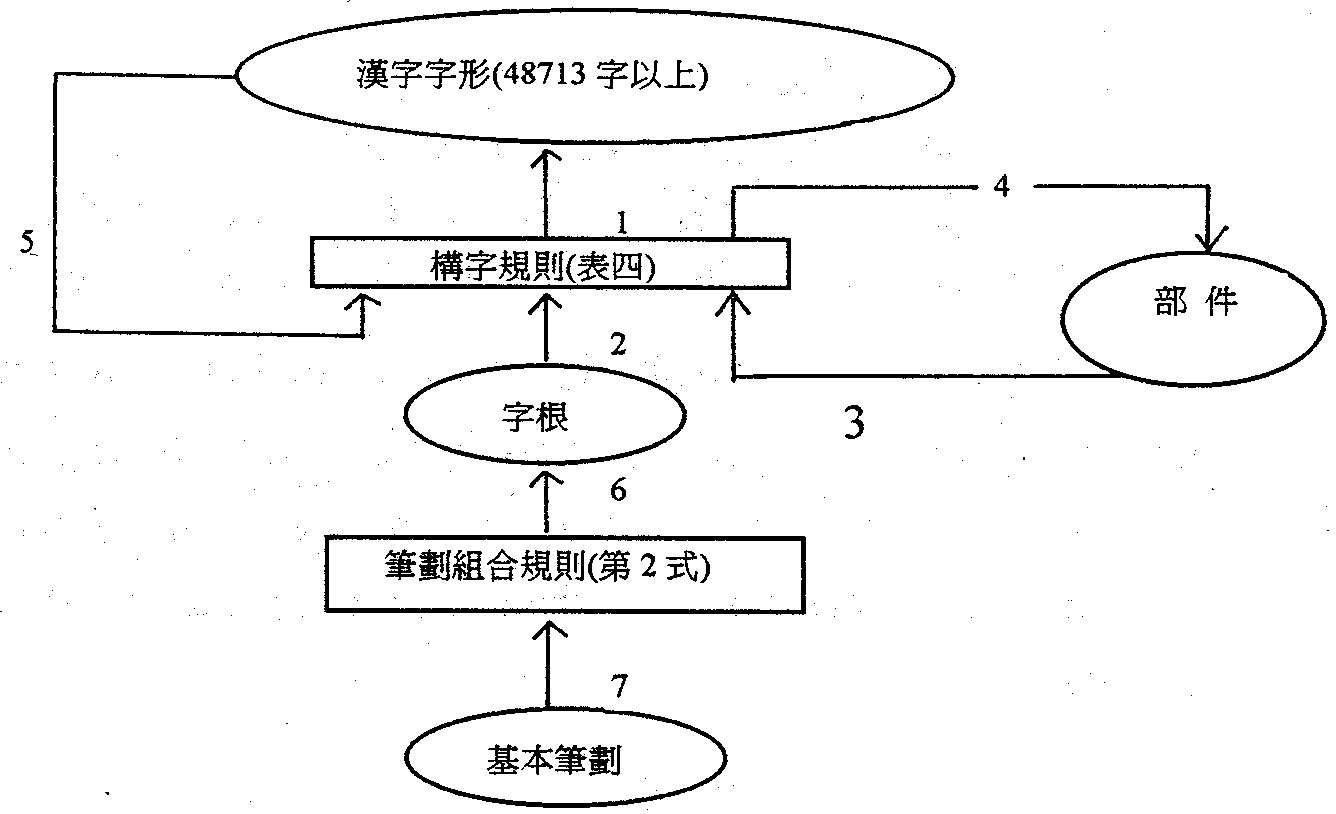
Our glyph model is shown in ĄeFigure 4Ąf. In this model, the part connected by line 12345is the formal system shown in ĄeTable 4ĄfĄCLines 6 to 7 show the composition of strokes to produce root. The decomposition of glyph into components can be expressed as in the following two equations. Figure 4
Let G be glyph, R be root, K be component, and T be basic stroke. Let p and s represent position and size , respectively, then GĄŚŁUK Ą]p, sĄ^.............Ą]1Ą^ RĄŚŁUT Ą]p, sĄ^.............Ą]2Ą^ Equation (1) is iterative and should be governed by the rules in ĄeTable 4ĄfĄC
Let us explain how the structure of a glyph is represented in computer by examples. In the tree shown below, the glyphs in right most branch can be expressed as
These equations are generally referenced as Ą§glyph structure expressionsĄš, or Ą§glyph expressionsĄš in short, in which r, s, andtrepresent the operations of Ą§vertical compositionĄš, Ą§horizontal compositionĄš, and Ą§contain compositionĄš, respectively. Although there is only one composition operator in each of the above equations, computer can iterate these expressions to obtain an expression solely with roots by eliminate components successively like follows. öèĄŚöòĄ]ÖĂò«AĄ^ In Equation 3, the glyph Ą§öèĄš is composted up by 8 roots. The glyph expression , such as Equation 3, solely by roots is called a Ą§root expressionĄš. Similarly, a glyph expression by components such as equation 1 to 11 described previously may be called a Ą§component expressionĄš. When all the operators are eliminated, Equation (3) becomes. öèĄŚöBÉ@ŻÉšőB„DĄKĄKĄKĄKĄKĄKĄKĄKĄKĄKĄKĄKĄKĄKĄKĄKĄKĄKĄKĄK.(4) Equation (4) is called Ą§the root sequenceĄš of öè. Following the same naming thought, equations 1 to 11 after eliminating operators may be called Ą§component sequencesĄš. In general, any representation called Ą§expressionĄš refers to a complete glyph structure information, while Ą§sequenceĄš does not. In other words, each glyph has an unique glyph expression and hence this expression can be served as the identifier of that glyph. Although Ą§sequenceĄš does not have complete structure information of glyph, it still has very high discriminating abilities among glyphs. For instance, in ȘLŸđŠr¶°of 9129 glyphs, there are only 8 pairs of glyphs have exactly the same component sequence, such as Ą]ĐùĄNûĄ^. All others can be uniquely identified by their component sequences. In practice, all of the glyph expressions of a character set can be stored in computer. By doing this, all the knowledge of glyph structure information of a character set has been formally represented and stored for further use. ForĄm€€€ćčqžŁ°ò„»„ΊrĄn, there are 9756 glyph expressions in which 8529 for authority character, 593 for variants, and 629 for components. While simplified characters are included, then, 2284 expressions are added for simplified variants and 35 are added for simplified new components. Thus, the number of component increased to 644, and the total number of glyph expressions increased to 11477. The 8529 expressions for authority characters remain unchanged. |
| Page 4 of 9 |
|