|
|
| �Ĥ@�������r�Ƿ|�dzN�Q�|�E�Ѭz 1996�~8��25-30�� �q�l�j�y�����ʦr���D |
| Page 5 of 8 |
| �ѡB�t�γ]�p�P���
�e��ͨ���D��;�I���M�@���[���B�z���A�b�����i�ѨM�ʦr���D�����C�ڭ̱N�c�r�Ҧ��B�հɹL���m��j�r�ڨt�Ρn�Ρm����q���Φr�n��b�q�����c���u�r�θ�Ʈw�v�A�Ʊ�H������¦�o�i�C�i���C�j �q��������A�K���F�A�ΨǸ��M�����u�{�N�A�����孫�I���b���A�G���H�r�ά�������Ȭ������i�����I�C
�@�B�t��z
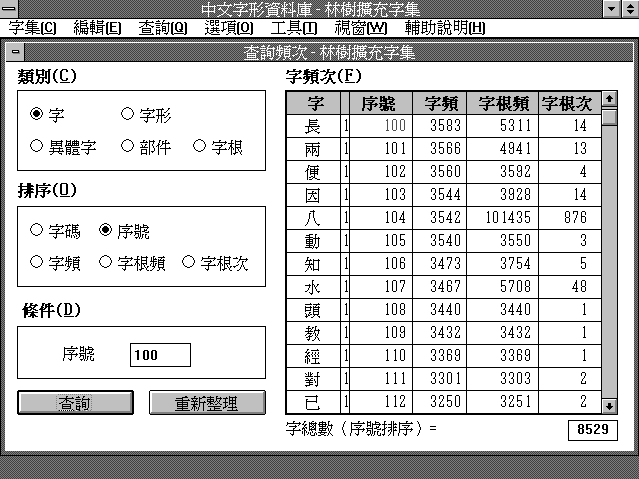
���t�άO�bIBM�ۮe���ӤH�q�����A�x�W���������3.1�@�~�@�~�t�ΤU�A��Visual Basic�{���y���o�i�C�t�Τ�����Ӹ�Ʈw�A�m�r�θ�Ʈw�n�Ρm��r�ݩʸ�Ʈw�n�A���O��Foxpro��Ʈw�z�t�Ϋإߪ��C �o�Өt�Φ��X�ӥΪk�C���t�Τ��|�L����A�άO�n���R�@�M�|�����J�t�Ϊ��r�ή��A�i�H�v�r�N�r�Ϊ����c����A�]�A��r�B�r�ΡB����Φr�ڡB�������C�H�H�����ʪ��覡�A�إ߹q�����������c�C�����A�Y����r�Φr�Ϊ��r�W�έp�A��i�@�ָ��J�d�ݫ�ΡC�@�M�r�θ��J���A�Y�i��o�M��r�@�U�جd���A�]�A�C�@�Ӧr�Ϊ��c���B�r�ڴF�Ū��B��r�F�Ū��B�H�Φr�ΡB�r�ڡB�����έp��ơC�䦸�A�Y���Y�r�Ϊ��c�r�ݤ���A�h�i�s�X�p������J�����r�ΥѤH����A�αN�Ӧr�����c��J�ѭp������C�Y�O����M�r�Χ��w���J�p������A�h�p����i�H�ԦC����M�r�Ϊ��t���C�i���J�p������r�Ϊ��M�Ƥ����C�`���V�h�A�h�V��Ѧһ��ȡC �ثe�t�Τw�g��J�F�T�Ӧr���A��@�O�հɫ᪺�m����q���Φr��s�n�A�@�� 8529 �Ӧr�A�t���ѷӦr�� 593���A����629���A�r��457�ӡC��G���e�z�r���A�[�W�j�����з�²�Ʀr�i���K�j�A�r�Ƥ����A�ѷӦr�μW�[��2284���A����664���A�r��492�ӡC�ĤT�Ӧr�����m�q�l���ɦr���n�A�u�����@�Ǿ��c�s�@�q�l���ɩүʪ��r�A�ثe��500�l�r�A�r�Ʃ|�b�W�[���C �t�Τ�����r�B�r�ΡB����B�r�ڡB�������e�{�覡�p�U�G
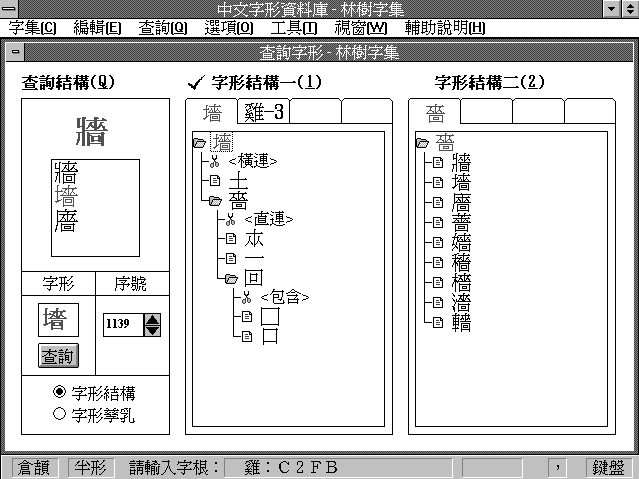
�̥��t�Ϊ��]�p�A�i�H�Ѻc�r�W�[���r���A�ѼХܤ��[��쵧�����ܤơF�o�ݤ����ڪ��u�r�ˡv�C�ثe�A�t�Υu�����e�ϥ|�f�����r�ε��c�����A�ܩ�ѵ����զ��r�ڪ������h�|�������C �r�θ�Ʈw���˯��k�Ǭ��r�άd�P�W���d�ߨ�Ӥ����C�r�άd�߮ɥi�d�r�ε��c�M�r�δF���A���Х��`�N�r�P�r�Ϊ��Ϥ��C�Ҧp�d���L���r�������u�١v�r���A�����e���W�|�ݨ�u��v�B�u�١v�Ρu�p�v�T�Ӧr��,�@�H�u��v���Ӧr�����зǦr�C�䦸�A�ëD�Ҧ����r�άҥi�ݨ��ڪ��u�r�ˡv�A��h�W�A�ڭ̨ä����o�Ǧr�y���A�ӬO�H�c�r�����ܡC�Ҧp�G�d�ߡu���v���A�i�ݨ�u���v�B�u��-3�v�Ρu��-4�v�T�Ӧr�ΡF�䤤�r�Ρu��-3�v���u�O�v��s�u���v�A�u��-4�v�h���u�S�v��s�u���v�C�r�άd�ߪ��e���p�e�ϤC�f�A�H�U²��C�X�d�ߪ���k�Ϊ`�N�ƶ��C
�ϤC�B�r�Ϊ��d��
�W���d�߮��A�����ܩ��ҿ蠟�r���B�d�ߤ���H�αƧǤ覡�C�d�ߪ���H���r�B�r�ΡB����r�B����Φr�ڵ��A�Ƨǫh�i�̦r�X�B�Ǹ��B�r�W�B�r���W�B�r�ڦ����ƦC�C�ܩ�r���W�Φr�ڦ����N�q�i�H�L���r�������r�Ρu�G�v�B�u���v���һ����G
�]�G�^�r�Ϊ����F�P�e�{ ���ڭ̥��ΨҤl�A�ӻ����@�ǦW���M�Ÿ��A�H�κc�r�H���b�q���������F�覡�C�e�Ϥ��f�̥k�@�K�����@�Ǧr�b�q���������F�p�U�G 1. ��������@2. ���������A�@3. ���פ����� 4. �����V�@5. ���פf���V�@6. �á��^��ɨ 7. �V�]���á@8. �A���@9.�����B��w�g 10.�^�B�@11. �����B��I�t��1��11�o�Ǧ��l�٬��u�c�r���v�A�䤤������O���ܾ�s�B���s�B�]�t���w��Ÿ��C�q���i�̺c�r���A�v���l�ܥH���h�������r�γ����A�ӱo�짹���H�r�ڪ��ܸӦr�c�����u�r�ںc�r���v�C�p(3) �G ��������]�����A�^ �@������]�]�^��ɨ�^��]�������^�^ �@������]�]�]�B�^��ɨ�^��]����]�B��w�^�^�^ �@����]�]�]�B��]�B��I�^�^��ɨ�^��]����]�B��w�^�^�^�K�K (3) (3)�������u��v�O�K�Ӧr�ںc�����A�Y�٥h�w��Ÿ��A(3)���i�g���G ����B�I�Bɨ���B�w �K�K (4) (4)���٬��誺�u�r�ڧǡv�C��Ӧ��k�A1��11���]�i�N�w��Ÿ��ٲ��A�ٲ��᪺���l�١u����ǡv�A�Ρu�r�ڧǡv�C �c�r�����֦��r�ε��c���㪺����A����ǩM�r�ڧǫh�_�C���M�p���A�r�ڧǪ��P�O��O�٬O�ܱj���A�b�L��r�����A�u���K��r�S�k�H�r�ڧǧP�O�A�p�]���B���^�C�O�G�b�P�O�r���A�Φr�ڧǤ������@�}�k�A����c�r����±o�h�C�i�O�A�b��ΤW���٬O���Ӫ��C��������M�ҧt���r�ΫH���̤��A���O����²��G�q�`�u���G�ӳ���]�����T�ӡ^�A�ӥB�ٲ����@�өw��Ÿ����j�����i�ѫe�᳡�ʽ褤�P�_�X�ӡ]�ιq���^�C�ҥH�A�Υ��Ӫ��ܩүʪ��r�O�ܤ�K���C �ڭ̥i�H��@�Ӧr�����Ҧ��r�Ϊ��c�r����b�r�θ�Ʈw���A�o�˫K����a�N�Ӧr�����r�ΫH���]�Ϊ��ѡ^��J�F�q���C�H�m����q���Φr�n�����A�@��9756�Ӻc�r���A�䤤8529���ݦr�����A593���ݲ���r�A629���ݳ��C�Y�N�Ӧr������M��²�Ʀr�]��i�h�A�h��2284���ݲ���r���c�r���A����[�h�F35�Ӧ@�p664���A��8529���ݦr�������¤����A�`�p11477�Ӻc�r���C �]�T�^�r���ܤƪ��Х� ��SGML�ӼХܯʦr����k�A�O��Wittern��App�������X���i���@�j�A�٬��u�~�r��Сv�]Kanji Placeholder�A²�٦�С^�C�~�r��гW�w�H�u���v�_�Y�A�H�u�F�v�����A�ӧ��b�䤤���r�������ӳ����A���O���ܸӦr�Φb�Y�@�X���Y�@��m�C �Q�Φ�����A�N�i�H�P���X�Ӥ��ɯʦr�CWittern��APP�غc�F�@�~�r�w�]KanjiBase�^�A�]�AJIS�ABIG5�]�Y���j�X�^�AUnicode��CNS���C�䤤CNS�����U�K�d�r�A�r�Ƴ̦h�AUnicode�����C�Y���ɧ@�~���J���ʦr�A�h�����bCNS���d�M�A�p�G���Ӧr�r���A�h�Φ�бNCNS���X�Щ��b��F�Y�L�A�AUnicode�C�Ҧp�G�u&U4AB5�v���ܤ@�ʦr�F�䤤U����Unicode�r���A4AB5���ܸӯʦr�r�Ϊ�Unicode�X��C �o�Ӥ�k�i�H��֯ʦr�A�O���Ϊ��F�ӥB���ĥΤF��ڪ��зǧ@�����X�������A���U��j�a�ĥάy�q�C�M���A�̫e�������Q���A�o�Ӥ�k�èS�������ѨM�ʦr�ұa�Ӫ��Ѧh�x�Z�C�A���A�ѩ�u���v�Q�ά�����X�A���y�峹���Y�n�Ρu���v�ɫ���O�H����SGML�O�ѨM�ʦr���D���O����k�A���t�αN�ץ��~�r��Ъ��@�k�A���X�Ī���סC�@ �~�r��ЬO�HSGML���Хܡ]tag�^�������A�Ψ�L�r�X�����r�ΨӪ��F�ʦr�C�馹�A�ڭ̥i�κc�r�H���A�Y�c�r���B�r�ڧǩγ���ǨӪ��F�ʦr�A�٬��~�r�μС]Kanji Glyphholder�^�A²�٧μСC�H����Ǭ����A�����p�U�C ���]�����ܼХܪ��_�I�]open delimiter�^�A�����ܵ����]close delimiter�^�A�h��g�����������i�ΡG�������H�H�H�������r�ڧǪ��ܡF�p�G�r�������u���H�v�r�A�]�i�����������H����������Ǫ��ܡC�o�˪����F�覡�A�i�H�K�h�d��L�r�X���u�@�A�ӳ��ҧt���H�������@���{�O�Ӧr�ʦr���ΡC �P�˪���k�]�i�ΨӼХܲ���r�C�ҥΪ���k�O�b�c�r���]�Φr�ڧǡB����ǡ^����Τ@�u�E�v�@�Ϲj�A�A���W�Ӧr���r�νX�C�ҥΪ��ХܻP�W�ۦP�C�p�A�u�����ġE3���v���ܡu���ӡv�A�Y�ӬO�Ī��ĤT�Ӳ���r�C �μШä��ư�����AWittern�MApp���~�r��Ф]�i�H��b���M���������C�ҥH�A�μХ]�t��Ъ��\���A���Ч��K�A�O��Ъ����ӡC �]�|�^�⩤�r�Ϊ��@�� ���F�⩤�r�ί�����q�@���A�ڭ��|�ձN²�Ʀr�Τj�����r�ڻP�u����v�ǤJ�t�Τ��C�b²�Ʀr�譱�A�O�ĥ�Ĭ�����ھ�1986�~�m²�Ʀr�`���n�ҽs���m�~�r�c²��Ӧr��n������²�Ʀr�C�ثe�w��J�P�m����q���Φr�n����ۤ�������2017���A�l�U������242�r���b�y�r���A�|����J�i���Q�j�C�ܩ�r�ڤ譱�A�h�ĥ��Z�~�j���m�{�N�~�y�w�q���R�n�Ѥ������ťéM���͡q�~�r���c�Ψ�c���������έp�Τ��R�r�@�夤�ҦC���r���A�H��ISO/IEC JTC1/SC2/WG2/JRG N319�����qISO 10646 Additional Components �r���r�ڡC�o�Ǧr�ڨå��@����J�t�Τ��A�ت��O�n���դG�̪��ۮe�{�סC���G��ܨ⩤���r�ڬO�Q���ۮe�F�[�F2235�Ӧr�Ϋ�u�W�[�F35�Ӧr�کM36�ӳ����A�䤤�h��²�ƪ����Ǥγ���C �b�r�ε��c�譱,�J��F�@�Ӱ��D�A���N�O²�ƫ᪺���ǩγ��ϥα��Ҫ������A�p�u�\�v����W�ϥ��A�礣�X�{�b�r�Ϊ��U��C�S�p�A��²�Ƭ��@�A�d²�Ƭ��@�A�«o²�Ƭ��@�A���O�@�C��O²�Ƭ��@���A�O���O�r����F�A�d��²�Ƭ��@�H�]�������O��r�C�ѩ���m�����A�ڭ̫����d���A�]�L�k��o²�Ʀr�ɩҩw���W�h�[�H�P�_�C�o�ب̱��Ҧӧ@���P²�ƪ����p�A�ϱo�b�F�ŵ��c�����ͤF�Ǩҥ~�C�]�o�F�ɩw�u����r�ڡv�����D�A�������A�S����k²��a�Τ@�r�ڴ��N�t�@�r�ڦӱo���c²����M�A�u���v�r�n�O��c�r�C�ڭ̬۫H²�ƥ����̾ڻP�W�h�A�Y�i��o�o�dzW�h�αN���ǤJ�q���A�H�K�t�Φa���F²�Ʀr�ΡC�ѩo�ر����A�]�ϱo���ǥi�H�u�����v��²�Ƴ����A�b�����ɲ��͵S���A�p��²�Ƭ��̍�k�AᨡB�~�Bή��T�r�b�r�夤�䤣���A�O���O�i�����O�H�άO�o�Ǧr�w�R���F�H �䦸�A�ڻD�j����z�L����r���A�b²�ƹL�{���X�֤F�Dz���r�A�p�^�B�X���B���B���X�֦����C�o���Τ]�]���ڭ̯ʥF�F�ѦӲ��Ͱ��D�G�s���^�B�X���B���B���٦b���bGB�r�����H���̬O�����F�H�άO����@����r�H�p�G����o����r���ά����H���A�ڭ̴N���|�p���L���Ӥ����ӫ�˳B�z�o�Ǧr�C ���~�A�b�����譱�]���Ǯt���A�p�G�u���v�P�u�f�v�A�u�f�v�P�u���f�v���C�o�Ǯt���Τ��@�r�˪���ƺɥi���F�A���Ӥ��|�y�����D�C�u�O�m�~�r�c²��Ӧr��n���䤣��k�r�A���M�b�T�B�[��r���i�H�L���A���`�O����ߡC�]�\�O�ڭ̥Ϊ��m�~�r�c²��Ӧr��n���Ӧn�}�A�b��Ʀ����W�ڭ�����V�O�C �`���A�c²�r�ΦX�֦b�r�θ�Ʈw���A�ثe�����ǰ��D�A���j��W�O�i�檺�B���\���C�e�z���x���[�j�F�r�ε��c�W�������{���A�ä��O������C �i���@�j Christian Wittern and Urs App.�qIRIZ Kanji Base : A New Strategy for Dealing with Missing Chinese Characters �r �@�ɹq�l���|ij(EBTI)�x�_�A1996�~4�� �i���C�j �²M�T�B���w���B�i�A���B�\���T�A�q����r�θ�Ʈw���]�p�P�B�Ρr�A�����r�Ƿ|�~�|�A�x��1995 �i���K�j
�̷ӡm²�Ʀr�`���n(1986�~��)�A�@��²�Ʀr2235�ӡA�ά۹������c��r2259�ӡC �i���E�j�Ԩ��\���T�A�q�L��r�����ΰ��D�r�r�A����|��T�Ҥ��m�B�z����ǡA1996 �i���Q�j�\���T�A�m�L���X�R�r������²�Ʀr�n�A���m�B�z����ǡA���z�|��T�ҡA1996 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Page 5 of 8 |
|