 |
|
�Ĥ��������r�ǥ���dzN��Q�| 1995�~4��29-30�� ����r�θ�Ʈw���]�p�P���� |
| Page 2 of 3 |
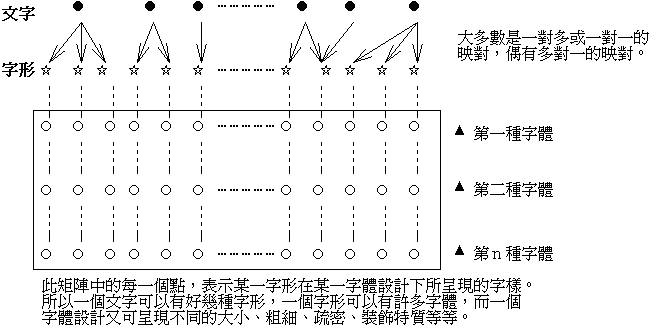
| �L�B��r�P�r�Ϊ�����F ����ĥΪ���r�P�r�μҦ��A�O�ھڥ��ꤻ�Q�@�~�o������j�r�ڼҦ��i���G�j�W�q�Ӧ����C�n�����A��r�O���F�@�ء]�Τ@�s�^�������W�ۡA�O��H���C�ڭ̥i�H�z�L�C��A�Ҧp�G�n���Φr�ΡA�N���e�{�X�ӥH�ϤH�i�H��ı�C�b���夤�A�Ȥ��Q�צr���A�u�Ҽ{�r�γ����C ��r�M�r�Ϊ����Y�O�G�@�Ӥ�r�i�H���\�h���P���r�ΡF�����A�]���Ǥ�r�|�άۦP���r�ΡC�ҥH�A�q�ƾ����Y�ӻ��A��r����r�άO�h��h���M��A���M�j�h�ƬO�@��h�����Y�C�r�Τ]�O��H���W�ۡA�ϧO�r�Ϊ�����b���զ����c�A��Y�c�r�C�ҥH�@�Ӧr�Υi�H���ܤƦh�m�h���������A�M�Ө�c�r���W�߫o���e����C �L���骺�r�Φ��@�w���]�p�W�d�A���q�P�@�]�p�W�d�s�@���@�s�r���ݩ�P�@�ئr��C�r��]�O��H���A�ϧO��������b��]�p���W�d�C�@�ئr��]�p�A�q�`���ǰѼƨӨM�w��r�e�{���j�p�B�ʲӡB���K�B�H�Τ@�ǯS���˹����䨤�����C�ݳo�ǰѼƿ�w����A�~��e�{�X�@�Ӧr�Ϊ������A�٬��r�ˡC�o�ӭ����N���O��H���ӬO����i�����F�C �W�z����r�B�r�ΡB�r��B�M�r�˪����Y�i�p�i�Ϥ@�j�ҥܡC�ҿp����Ϊ���r�P�r�μҦ��A�N�O�n��o�ǩ�H���W�۩M�������c�r�B�]�p�W�d�A�H�Ω����������Y�M�B�@�W�ߵ��A�έp�����F�Ѫ��Φ����F�X�ӡA�H�K�p�������B�γo�Ǫ��ѡA���ڭ̰��ơC |
�Ϥ@�G��r�B�r�ΡB�r��M�r�˪����Y
| �@�B�r�����F�~�r������
(component)
�c���C���c���O���W�ߪ��A�i�k�Ǭ�²�檺��W�h�C�b��j�r�ڨt�Τ��A�N�~�r�r�ΥH��s(H)�A���s(V)�A�M�]�[(C)���ѡA�o��496�Ӱ�����A�٬��r���C�o�s�r�کM�զX���W�h�]��Y���Ѫ��W�h�^�i�H�զ�48713�Ӻ~�r�A���F�@���������˪��j�r�~�A�X�G�i�զ��Ҧ����~�r�A�B�㦳�Ш�s�r���\��C�ҥH�ڭ̱ĥγo�M�r�ڨt�Χ@���]�p����¦�C
�䦸�A�r�ڥѵ����զ��C�L����]�p�ҥΪ������ƥج��T�Q�ܤ@�ʾl�����C���A�T�Q�X�Ӱ����w�����{�A�Ψ�@�ʦh�ӵ����u�O���F���n�ӳ��������H���Ʀr�˦Ӥw�C�ڭ̪��t�έ��I�b��{�r�ΡA�ҥH�Ϊ��������h�]�ƹ�W�A�i�ѨϥΪ̦ۤv��ܵ������h��^�C�r�ΡB����B�r�ڡB�M���������Y�p�i�ϤG�j�ҥܡC |
�ϤG�G�r�ΡB����B�r�کM�������ϫY

�@
| �b��ڹB�@�ɡA�o�˪��t�η|���ͤ@�Ǹ����������ܦ��C�Ҧp�G�i�ϤT�j���W�r�C�ҥH�b�]�p�ɡA�ڭ̾��q��c�r�W�h²�ơA�H�Q����C���k�O�G�b�զX�]�Τ��ѡ^�@�Ӧr�ήɡA�@���u�Τ@�ӲզX�]���ѡ^���B�@�A�Y��ξ�s�B���s�B�]�[�䤤���@�C�Y�٨S�����Ѧ��r�ڡA�h�N�ͦ�������A���ѡA���즡���u���r�ڬ���C�ѩ�r�ڼƥؤ��h�A�����զX�W�h�N�̨䵧���ͦ�����m�v�@�Щ��C
�W�z���c�r�����i�H��²�檺�ƾǪ��F�A�O�G�i�H�έp����B�z�C�b�i���G�j�Ҥު��U�ѦҤ�A���ԲӪ��ԭz�A�ЦU��ѦҡC �ϤT�G�W�r���c�� �G�B�r���ܤƪ����R �ھڤW�z���r�μҦ��A�r�Ϊ��ܤ����h�A�o�i�H�k�Ǭ��������ܤơB�r�کγ����ܤơB�M��Ӧr���ܤƵ��T�ӵ��šC�o�ع����k�A���̴��b���إ����r�Ƿ|���i�L�]����78�~12��^�C�{�ȱN��j�n�`���p�U�G(�@)�B�������ܤ�
�]�G�^�B�r�کγ����ܤ�
�H�W�o�ؤ��k�A�O�����q�r�εۤ�����C���A�|�i�[�`�q��r�Ǩ��ת��[��A�Ҧp�G�n�Ū����N�h�ݦr�کγ����ܤơ]��Y��B�Ũ��)�C�o�Ǥu�@�A�d�ݥH��ɥR�C �T�B�|�� �{�b�A���ڭ̥Τ@�Ӹ����㪺�Ҥl�A�H���Ϋe�z�����F�覡�C���]G�N���r��(Glyph)�AR�N������(Component)��R0�N���r�ڡAT�N�������Ap�Ms���O�N��T�MR�b�r�Τ�����m(position)�M�j�p(size)�A�h�@�Ӧr�Ϊ��զ��A�i�ΤU���G�ӦA�ͦ�(recursive equation)���ܤ��G
ƫ�]1�^�����N��O�GG�ѳ\�h�]�H�U���ܡ^R�զ��A�ӨC��R�b�r�Τ��������S�w����m�M�j�p�]�Yp�Ms)�C�]1�^���i���ƨϥΡA����Ҧ���R����²��R0����C��R0�A�ھڡ]2�^���A�i�A���Ѭ��@�s����T�A�C�ӵ����禳���m�M�j�p�����Y�C �F�ѳo�DzŸ���A�i�ϥ|�j�M�i�Ϥ��j�Y���O�q��Ө��סA�ӻ����o�ؼҦ������ΡC�i�ϥ|�j���ܪ��O�@�Ӥ�r�u�_�v�B������Ӧr�ΡB�@�dz���M�r�ڡA�M�����������զ����Y�F�H�Φr���ܤƩҥ[������(tags)�C �i�Ϥ��j�O�@�Ӧr�ڡuɨ�v���r�δF�ž�C�b�餺���O�r�ΡA�S�骺�O�r�کγ���C�Ϥ��r���ܤƪ����ѡA�H��u���O���ܡC �b�p����̡A�i�ϥ|�j�M�i�Ϥ��j���O�q�@�ӵ��c�����ɥX�Ӫ��C�i�ϥ|�j�O�Ѧr�α��ɨ쵧���A�ӡi�Ϥ��j�h�ۤϡA�Ѧr�ڱ��ɨ�Ҧ���������r�C �ϥ|�G�_�r������ �r�βզ� �Ϥ��G�r�δF�ž𤧨��i���G�j�@�аѷӡG�²M�T���դ���r�ڤ����R�֡A��j�ǥZ�Ĥ����Ĥ@�� pp.112-121,1972�C���~�A�B�F�H���s�ۡm�~�r��X���ަr��n,(Asian Associates�X���A�����|�Ϯ��]�d���G790525, 1979)�]�ĥΦ��Ҧ��C�S�A���Ҧ�����g�� AF11���<On the formalization of glyph in Chinese Language>1990,2��C |
| Page 2 of 3 |
|


