|
|
| �Ĥ@�������r�Ƿ|�dzN�Q�|�E�Ѭz 1996�~8��25-30�� �q�l�j�y�����ʦr���D |
| Page 7 of 8 |
| �v�B����
�b�������A�N�|�T�ӻP�ʦr���������Ψ̦������C�������i�Υ��t�γ]�k�ѨM�q�l���ʦr���p�e�C�䦸�A���ЧQ�Φr�θ�Ʈw��}��Ƶn���t�Ϊ��W���C�̫��AIJ�ήڥ����D�A�Ʊ�q���媺�z�P�g�礤�A���s�Ҷq�洫�X���]�p�C�����y���ʦr���D�������A�N�O�ثe���洫�X�C
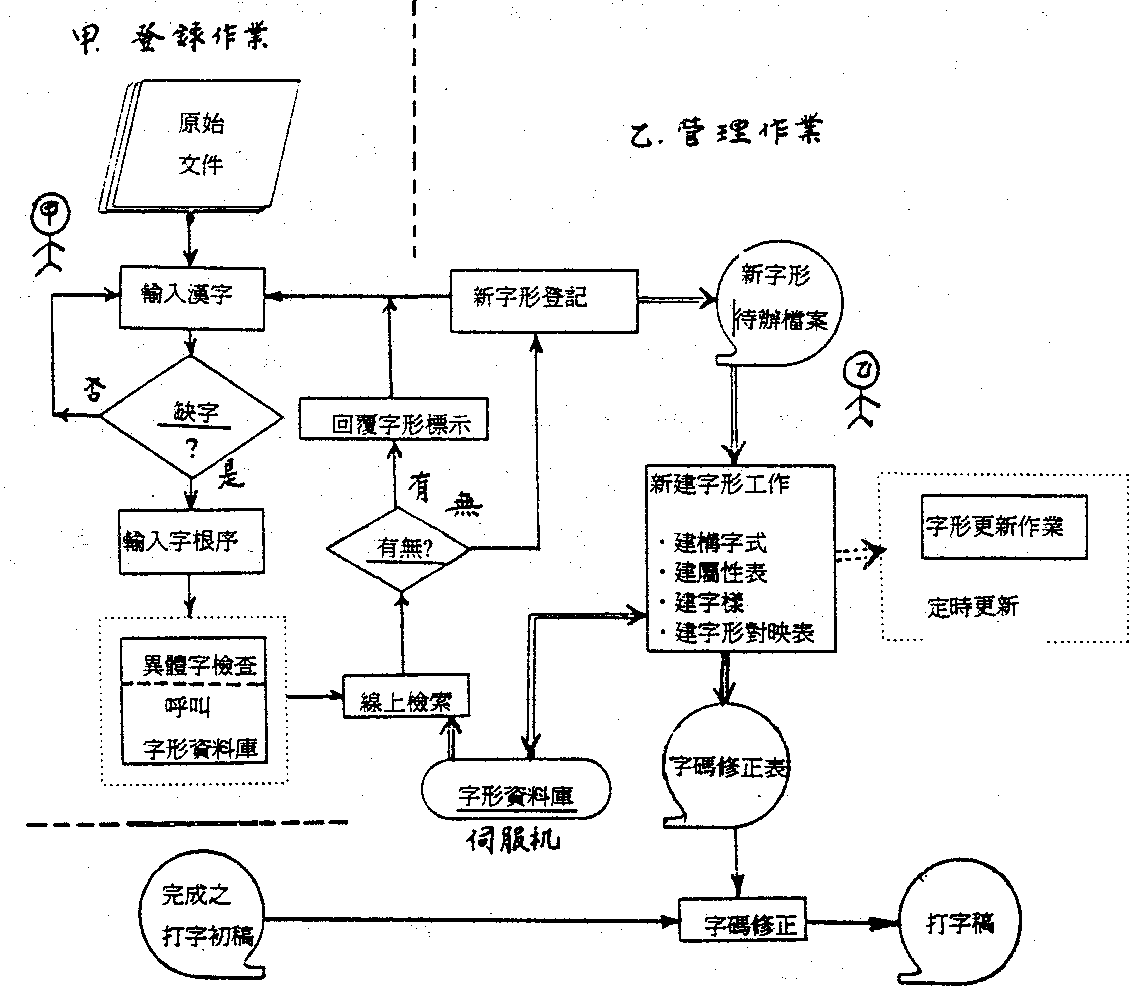
�@�B�q�l���ʦr���ѨM���
��Ш��y�h�ݥj���A�䤤�`�����ɳq�Τ��r���A�P�{�N���u�зǡv�r�Ψä��@�ˡC�b�x�W�A���\�h���c���b�s�@�q�l����A�@�h���F�y�q�A�G�Ӭ��F�O�s���y�C�i�O�A�ʦr���D�o�y���y�q�M�O�s�W�P�R����ê�C�����A�x�W�j�Ǥ�ǰ|��Ǭ�s�����ܶ��U���c�A���@�s�@�M�m�q�l���ɥR�r���n�ӸѨM���D�C�X�g��ij�A�P�N�ѥ�����ǭt�d�N�u�@�C�o�Ӥu�@�W����O�@�Ө嫬�ѨM�ʦr����סC
�ѥ[���c�һs�@����Ш��y�A�p���G�m�j��Y�g�n�B�m�I�án�B�m����j���n�B�m�B�֫O������n�B�m�߾����n�B�m�j���òĤE�U�n�A�H�Ϊ�N���M�ѡm�������n���C�U���c�����ʦr�A�ìd�����ݩʫ��A�e�楻����ǦX�ֳB�z�C
���w�����ʹ��N�e�Ӫ��ʦr���H���R�A�o�{�Ʀh�O�ѩ�r�餣�P�Ӳ��ͪ����@�r�ˡC�o�Ǧr�ثe�Ȥ��B�z�A�l�̤����p�e���E�f�C�����A���ĤG���ݵ��c�ܤƥ~�A�l���ݦr�ڻP�����ܤơC�o�Ǧr�j�h�O����r�A�i�n���b�r�θ�Ʈw���A�ثe�w�s�J500�h�r�C�i���Q�@�j
�o�Ǧr�s�JBig-5�X���A�禳�W�w�A�Ԧp�e���Q�f�C�ѩ�y�r�Ŷ��u��5809���A�b�ϥΤW�ܤ����������γy�r�ϤαM�ݳy�r�ϡC�Y�y�r�ϥ��W���������A���m�γy�r�ϡF�W�����C���A�h�̭ӧO���ݭn�Ӹm�J�M�ݳy�r�ϡC�M�Ӧb�y�r����A�Y�L�W�����έp����A�i��������g���D�G�媺�Φr�C���Φr���F�~�r�H�~�A�٦��S���Ÿ��A�]�A�~��r���B�y�����Φ��`�Ϊ��Ÿ��C�y�������s�����u���B���B���K�K�v�B�u�@�B�G�B�T�K�K�v�B�u���B�L�B�ѡK�K�v�B�u�ҡB�A�B���K�K�v�B�u�l�B���B�G�K�K�v���A�~�ؼ˦��h���u���B�]�^�B���K�K�v���A�H���j�X�������y�r�Ŷ��A�ۤ��i��N�o�Ǭy�����q�q�����A�ثe�u���y�����w�d100�Ӧ�l�C
�`�Ϊ��~��r���]�A���B�ڧQ��B�ä�Τ��C�y�r�ϲĥ|�qC6A1-C8FE�b�ʤѤ���t�ΤU�t���w�q�A�䤤�N�]�A�F���r���A�����U�ʤѤΤ�������ϥΪ��@�P���A�o�@�q�ڭ̤��ΡC�t�~�̾ڻO�j��Ǭ�s���ߡu�����ù���r��g�P����n�骺�ۮe���D�v�Q�|ij�����A��ų�j�X�y�r�Ŷ������A�ثe�u����32�ӱ��B�ڧQ����ä媺��g�r���C�W���U���A�u���൹�ɥR�r���Ϊ����|�d�Ӧr���A���ӥi�H�Τ@�q�ɶ��C�p�G�o�|�d�Ӧ�m�����F�A�h�i�Φr�Φ�ШӭɥΨ�L�X���y�r�Ŷ��s��C
���E�G����ʦr������
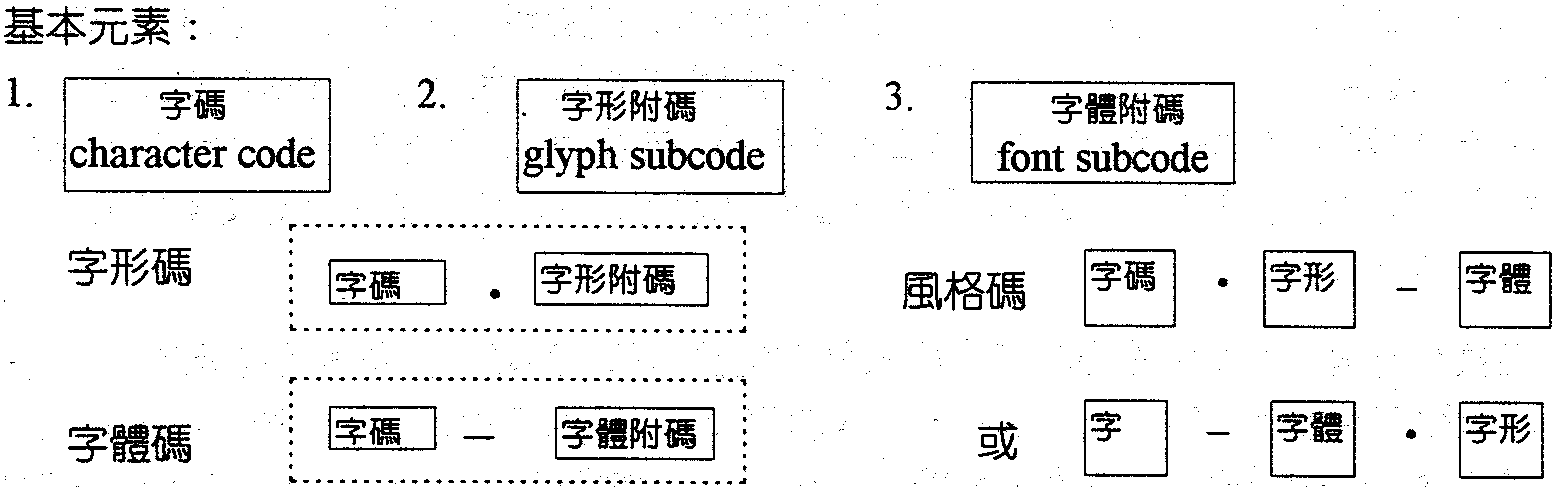
�@ �T�B��}�洫�X����ij �ثe�洫�X���ڥ��f���A�O����r�η��@�r�C�b���W�ꤣ�Ū����ΤU�A�W�s�r�X�]character code�^�ӹ�ڤW�o�H�r�Ϊ��t���ӧP�O�r�C�Ҧp�A���j�X���ȡ]C4C8�^�M���]B047�^���O����ӽX��C���̬O���O�P�@�Ӧr�O�H�̽X�����w�q�A���O�F���b�y�ΤW��b�O�P�@�Ӧr����ӧν}�F�C�o�ر��Φb�U�洫�X�����ҬO�AUnicode�MISO10646�]���ҥ~�C�q��r�ǩM�y���Ǫ����ݨ��A�o�ؤ�r���Ѫ����F�ڥ��O���~���A�����d���C�q��Ǫ����רӬ��A�w�q�����F�A������t�i�H�ŽסC���o�ؤ����d���]�p�A�ɭP�ثe���ΤW���̨��y�A��f�ʥX�A�ä��O�N�~���ơC�n�ﵽ�洫�X�A�����q���B�U��C ���~�A�����~�r���X�q���X�ת��[�I�ӬݬO�@�Ӷ}�X�]open set�^�A�H�ɥi��W�[�r�C���M�ʳ������r�����X�]close set�^���P�A�r���O���|�A�W���C�o�ǰʽ誺���P�A�N�ɭP�䤣�P���ʽ�M�B�z�覡�C�i�O�A�ثe�����k�o�O�M��ISO 646�B�z�r������k�A�ӽs�~�r���X�C�o�u�O�d���A�i�C�H�W�������M����O�Ʊ�j�a�F���A�n��}�{�����洫�X�����n����J������ұ_���A�_�h���|�������ѨM����k�C�H�U�N�O�ڭ̮ھڤW�z����h�A��ﵽ�{���洫�X�Ҵ��X����סC �]�@�^�T�q�����s�X �����A�ڭ̫�ij��r�B�r�ΡB�r����T�q�s�X�A�p�e�ϤQ�f�G
�ϤQ�G�r�X �B�r�νX�B�r��X�B����X�����Y �Y�r�Ϊ��X�P�r����X���ή��A�h�e�ᤣ���A���ɭY�u��r��ӵL�r���Ѽ��A�h�٭���X�]style code�^�A�Y�t���r�ΰѼ��A�h�٬��r�˽X�]type face code�^�C�r�X���ϥλP�{�b�ϥΥ洫�X�ۥΡC�r�νX�B�r��X�A����X�Φr�˽X���A�h�i�H�Ϋe�z���~�r�μи����P�r�X�@�_�ΡC�r�˽X�i������A�]���䤤�i��]�A�\�h�r�����Ѽ��A�o�L������D���A�Ա����Ӥ��͡C�r�Ϊ��X�u�O�@�ӥ���ƪ��s���C�b���t�Τ����i�H�ΨӰϧO����r�A�]�i�H�ΨӦs��Y�r�����ҥΪ��r�ΡC�Ҧp�A�ڭ̧�m����q���Φr�n�������c���b�r�Ϊ��X��������m�A��j���з�²��r��b������m�W�C�o�˨ϥΦr�Ϊ��X���覡�i�H�s���h����r�H���C(�G)�U�X���F������� �o�ؽs�X�覡���ϥΥi�Ѩ�ǿ饢�u���{�פW�����U�C�|�زզX�G �H�W�|�ر��Υi�r���ϥΥH���I���P���ݨD�C�o�O�����T�q�X�ണ�Ѫ��u�ʡC �]�T�^�c�r�����B�� �C�Ӧr�Ϊ��c�r�������ۦP�A�ҥH���i�Χ@�r�Ϊ��ѧO�X�C�o���Φb�Q�~�r��ФΧμЮɤw�z�ΡC���`�������[���b�]�p�洫�X���i�వ�k�C �κc�r���@�r�νX�̤j���n�B�A�O���O�@�ӫʳ��t�ΡG�u�n���@�ӫʳ����r�ڶ��X�A�t�H�e���|�f���W�h�A�N��F�C�p���K�i�٥h���d�W�U���X��C�m��j�r�ڨt�Ρn��496�Ӧr�ڴN�ಣ��48713�r�Ϊ��X�A�åB�٦����ݭn�ק�t�δN���I�s�r�ίʦr���u���A�N�O�̦n���Ҥl�C�䦸�A�c�r���O�@�ت��Ѫ��F�A�����ȸ��Ʀr�X��Ū�����A�ҥ��ê��c�r���ѧQ�����ε{�����B�z�C�M���A�������I�O�c�r�����u���@�A�]�����Ӫ��A�H�P�ΰ_�Ӹ����g�١C ����ǩήڧǸ��c�r��²��\�h�A�Υ��̨Ӵ��N�c�r���O�ܦ۵M���Q�k�C�H�m����q���Φr�n��9122�Ӧr���A�[�W629�ӳ����A457�Ӧr���A��i����48713�Ӧr�ΡC����9122�ӧΥu�Τ@�r�X�A�Ө�l��4�U�r�A�C�Ӻc�r�ǫo�i²��p15������11�Ӧ��l�C�������A�i�κ~�r�μШӪ��ܳѤU���|�U�r���A�C�Ӧr�Τ����ȤG�ΤT�Ӧr�X�C�ѩ�9122�Ӧr�Ϊ��ֿn�ϥ��W�v�w����99.9%�A�l�U�d�����@�H�U�����|�θ������X�A��t�Τ��IJv�v�T���������C�ҥH���κc�r����O�ﵽ�ثe�洫�X���@�Ӧn��k�C�i���Q�@�j �Ԩ����w���A�q���@�γy�r�����W���r1995�A�Ρq���@�γy�r������z�r�A1996�A���m�B�z����ǡA����|��T�� |
| Page 7 of 8 | |||
|